
On November 18 2025 a major global internet disruption originated from Cloudflare that affected websites applications and digital services worldwide. The issue began around 11 20 UTC when Cloudflare’s network experienced significant failures in routing core traffic. According to the company the failure stemmed from an internal change rather than malicious activity. The Cloudflare Blog+1
How the Outage Started
A change to a database system’s permissions caused the system to output multiple entries into a configuration file used by Cloudflare’s Bot Management system. That file grew beyond its expected size and when distributed network wide it exceeded the software’s limits and triggered service failures. The Cloudflare Blog+1
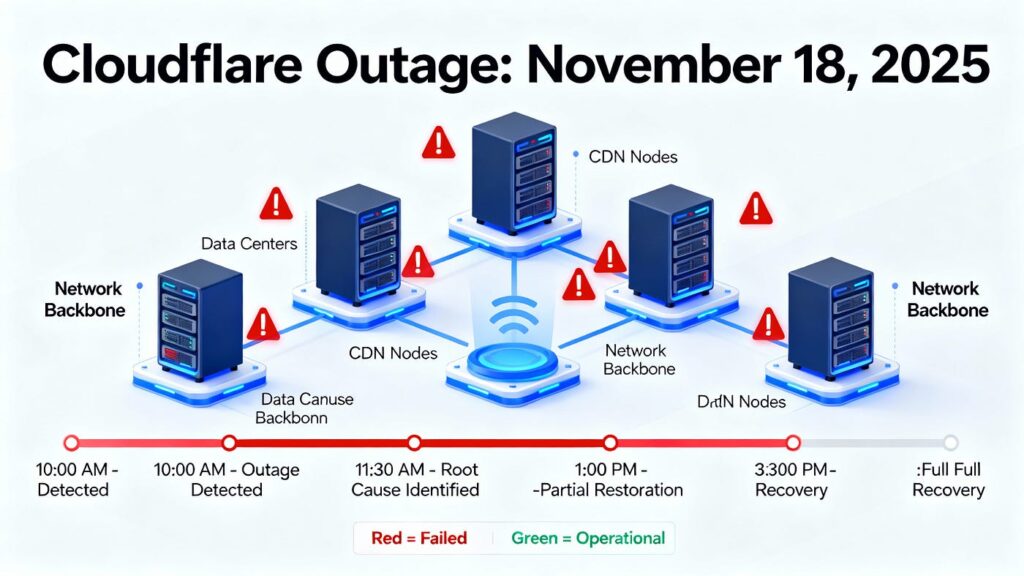
Timeline of Events
- At around 11 05 UTC a database access control change was deployed. The Cloudflare Blog
- The first errors were observed around 11 28 UTC when customer traffic began failing. Medium+1
- At 13 05 UTC the team implemented bypasses for certain services to reduce impact. Medium+1
- At 14 24 UTC propagation of the bad configuration file was halted and a correct version began deployment. Medium+1
- By 17 06 UTC all downstream services were fully restored and operational. The Cloudflare Blog
Impact and Services Affected
Because Cloudflare underpins a large portion of internet traffic many services such as content delivery security modules and authentication systems were impacted. HTTP 5xx errors reached elevated levels and end users encountered failed page loads login issues and disrupted access flows. The Cloudflare Blog+1
Why This Outage Matters
This incident illustrates how much today’s internet relies on major infrastructure providers. A single point of failure in a core system triggered cascading effects across numerous apps and websites. It shows that not all failures are caused by external attacks rather they can originate from internal configuration or automation errors. For businesses dependent on digital availability the event underscores the importance of architecture that anticipates failure rather than assuming constant continuity. Krebs on Security+1
Lessons for Businesses and IT Teams
- Map your dependencies on upstream infrastructure providers and evaluate what happens if one fails.
- Implement fallback paths and contingency plans to ensure partial continuity when upstream services degrade.
- Monitor not only your own systems but also the health of third-party services you rely upon.
- Review how your security perimeter behaves when a protective layer is weakened or bypassed.
- Treat outages as inevitable and build resilience into systems rather than assuming zero downtime. Krebs on Security
Cloudflare’s Response and Follow-Up
Cloudflare’s post-mortem acknowledges the error and outlines steps to harden systems: improving configuration ingestion controls deploying global kill switches for features reviewing failure modes and reducing risk of similar propagation issues in the future. The Cloudflare Blog
Final Thoughts
The November 18 outage reminds us that even the most advanced infrastructure providers can experience major disruptions from internal changes. For any organization that relies on digital services availability resilience is now a competitive advantage. Architecture strategy monitoring and dependency management deserve the same attention as feature development.
Sign up For Newsletter!!





Leave a Reply